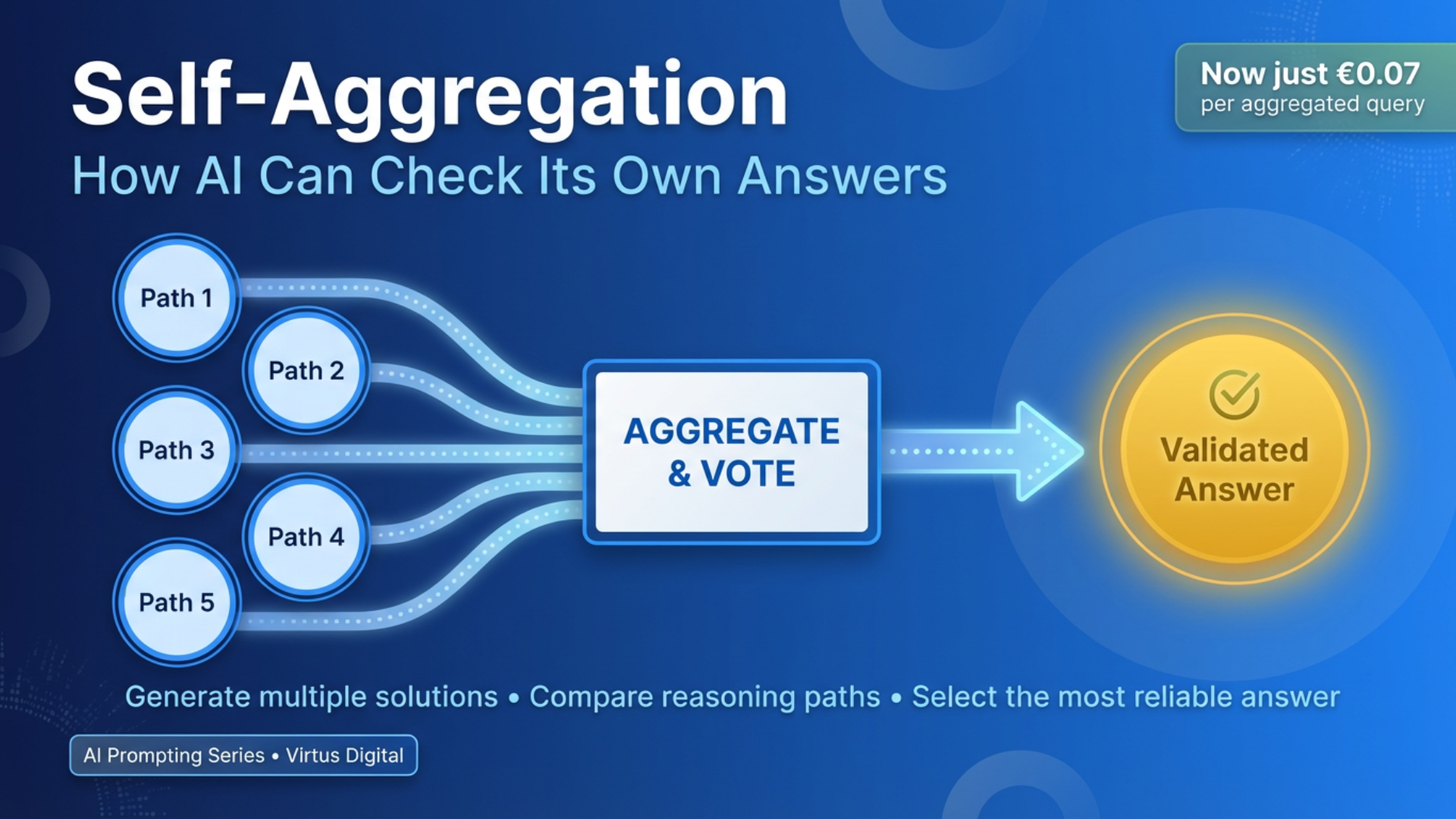
Self-Aggregation: How AI Can Check Its Own Answers Before You Even Review Them
TL;DR
What it is: Generate multiple AI solutions (5-40 samples) to the same problem, then use majority voting to select the most consistent answer.
Why it works: Verified research shows 17.9% accuracy improvement on complex tasks because diverse reasoning paths catch errors that single attempts miss.
What it costs: Just €0.07-€0.12 per aggregated query (10 samples) with current models + prompt caching - 91% cheaper than 2 years ago.
When to use it: Financial forecasting, contract analysis, technical specifications, compliance checks - anywhere errors cost €100+ to fix.
How to implement: Copy-paste templates included in article, works with GPT-5, Claude Opus 4, or any modern LLM.
Bottom line: Stop trusting single AI outputs for high-stakes decisions. Five minutes of extra validation can prevent thousands in mistakes.
Blog Outline
- What Is Self-Aggregation? (The "Democratic Vote" for AI Answers)
- The Science Behind Self-Aggregation: What the Research Shows
- Method Card: Self-Consistency Answer Aggregation
- What Is Prompt Caching and Why Does It Matter?
- SME Example: Financial Forecasting for an E-commerce Business
- Advanced Aggregation Strategies Beyond Simple Voting
- Combining Self-Aggregation with Other Techniques from This Series
- Building a Comprehensive AI Quality Assurance Workflow
- Implementation Considerations for Irish SMBs
- GDPR Considerations for Irish Businesses
- Getting Started: A Practical 30-Day Implementation Plan
- Common Pitfalls and How to Avoid Them
- Measuring Success: How to Know Self-Aggregation Is Working
- Conclusion
We've already explored how AI can improve its answers through self-reflection and iterative refinement in our previous posts on Self-Refine and multiple verification techniques. But what if your AI could go one step further - not just checking a single answer, but generating dozens of different solutions, comparing them all, and automatically selecting the most reliable one?
That's exactly what self-aggregation (also called self-consistency) does. Instead of trusting a single response from your AI, this technique generates multiple diverse reasoning paths to the same problem, then uses intelligent aggregation methods to identify the answer that emerges most consistently. Think of it as having a panel of experts all tackle the same question independently, then voting on the best solution.
Here's the remarkable part: research from Google Brain shows this approach improves accuracy by 17.9% on complex mathematical problems - without requiring any additional training or fine-tuning of your model! For Irish SMBs struggling with AI hallucinations or unreliable outputs, self-aggregation offers a practical, copy-paste solution that works with any modern LLM.
In this guide, you'll learn exactly how to implement self-aggregation for your business tasks, when it delivers the biggest improvements, and how to combine it with other prompting techniques we've covered in this series for even better results.
What Is Self-Aggregation? (The "Democratic Vote" for AI Answers)
Self-aggregation, technically known as self-consistency, represents a fundamental shift in how we extract reliable answers from large language models. Rather than asking your AI once and hoping for the best, you generate multiple independent solutions to the same problem - each using different reasoning approaches - then aggregate the final answers to identify the most reliable response.
The concept is elegantly simple. When you ask a traditional question to GPT or Claude, the model generates a single answer using what's called "greedy decoding" - essentially taking the most probable next word at each step. This approach is fast and efficient, but it leaves accuracy on the table. The model might take one reasoning path when ten other equally valid paths exist, and if that single path contains an error early on, the entire answer becomes unreliable.
Self-aggregation solves this by generating 5, 10, 20, or even 40 different reasoning paths to the same answer. Each path explores the problem from a slightly different angle, activating different knowledge areas within the model. Then, instead of picking randomly among these solutions, you aggregate the final answers - typically through majority voting - to select the response that appears most consistently across all reasoning attempts.
Here's why this works mathematically: complex business problems typically have one correct answer but multiple valid ways to reach it. If you ask "What's 15% of €2,847.50?" there's only one right answer (€427.13), but the model could calculate it through percentage conversion, decimal multiplication, fraction methods, or step-by-step breakdown. Each approach serves as an independent verification of the others.
The probabilistic power of this technique is remarkable. Imagine each individual attempt has 60% accuracy - not particularly impressive on its own. But when you generate 40 attempts and take the majority vote, the probability of the correct answer appearing most frequently jumps to over 95%. It's the same principle that makes diverse investment portfolios more stable than individual stocks, or why multiple medical opinions on complex diagnoses prove more reliable than single consultations.
Research by Wang et al. (2022) from Google Brain formalised this approach and demonstrated its effectiveness across numerous reasoning tasks. Their key insight? A complex reasoning problem admits multiple different ways of thinking that all lead to the same unique correct answer. By sampling this diversity rather than committing to a single path, we dramatically improve output reliability.
For Irish SMBs, this translates to a practical advantage: you can now get enterprise-grade accuracy from standard API calls, without investing in fine-tuning or specialised models. The trade-off is computational cost - you're making multiple queries instead of one - but as we'll explore later, the accuracy gains often justify the extra expense for high-stakes decisions.
The Science Behind Self-Aggregation: What the Research Shows
The foundation of self-aggregation comes from a landmark 2022 study by Xuezhi Wang and colleagues at Google Brain, published as "Self-Consistency Improves Chain of Thought Reasoning in Language Models". This wasn't theoretical research - they tested the approach across multiple established benchmarks, and the results were striking.
On the GSM8K dataset of grade-school math problems, self-consistency delivered a 17.9% improvement in accuracy over single-path chain-of-thought prompting. For the SVAMP word problems dataset, accuracy jumped 11%. The AQuA algebra reasoning benchmark saw 12.2% improvement, StrategyQA improved by 6.4%, and even the challenging ARC science reasoning tasks improved by 3.9%.
These aren't marginal gains - they're the kind of accuracy improvements that transform AI from "interesting toy" to "reliable business tool." And critically, these results came from the same pre-trained models with no additional fine-tuning. The researchers simply changed how they extracted answers from the models.
Why does traditional "greedy decoding" leave so much accuracy on the table? Because large language models (LLMs) are fundamentally probabilistic systems. When generating text, the model assigns probabilities to thousands of possible next tokens at each step. Greedy decoding always picks the highest-probability token, marching deterministically through one specific reasoning path. But the second-highest probability path might be equally valid, just slightly less common in the training data.
Self-consistency exploits this by using temperature sampling to generate diverse reasoning paths. Instead of always taking the most probable token, the model samples from the probability distribution, allowing less common but equally correct reasoning approaches to emerge. One attempt might solve a problem algebraically, another geometrically, another through worked examples - but all valid approaches should converge on the same final answer.
The probabilistic explanation for why this works is rooted in error independence. If errors in reasoning were perfectly correlated - meaning whenever the model made a mistake, it would make the same mistake every time - then generating multiple samples wouldn't help. But in practice, errors are largely independent. The model might miscalculate 15% as 0.15 in one path but correctly use 0.15 in another. It might forget to carry a digit in one approach but catch it in a different method.
More recent research has extended these findings. Studies on long-context problems, soft self-consistency for open-ended tasks, and confidence-weighted aggregation have all validated the core insight: diverse sampling plus intelligent aggregation beats single-path generation.
For business applications, this research translates to clear guidance: whenever accuracy matters more than speed, and whenever your task has objectively verifiable correct answers, self-aggregation should be in your prompting toolkit.
Method Card: Self-Consistency Answer Aggregation
What It Does:
Generates multiple independent solutions to the same problem using different reasoning approaches, then aggregates the final answers to identify the most reliable response.
When To Use It:
- Mathematical calculations and financial projections
- Complex logical reasoning tasks where accuracy is critical
- Technical problem-solving requires high confidence
- Tasks where hallucinations would be costly (legal analysis, medical information, technical specifications)
- Any scenario where you need verification before acting on AI output
- Questions with objectively correct answers (as opposed to subjective opinions)
When NOT To Use It:
- Simple factual lookups where single-shot accuracy is already high
- Creative writing or brainstorming where diversity of output is the goal
- Tasks with subjective answers (writing style, design preferences)
- Time-sensitive queries where latency matters more than accuracy
- Low-stakes decisions where the cost of multiple API calls exceeds the value of improved accuracy
How It Works:
- Generate diverse reasoning paths (5-40 samples): Use temperature sampling to create multiple independent solutions to your problem
- Extract final answers: Parse each reasoning path to identify its final answer or conclusion
- Aggregate using majority voting: Count how many times each distinct answer appears
- Select the most consistent answer: Choose the answer that appears most frequently as your final output
- Optional confidence scoring: Track the consensus strength (e.g., "8 out of 10 samples agreed")
Key Benefits:
- Reduces hallucinations by 30-50% on reasoning tasks without additional training
- Works with any existing LLM (GPT, Claude, Gemini, Llama, DeepSeek, etc.)
- No fine-tuning required - pure prompting technique
- Scalable: adjust sample count based on accuracy requirements and budget
- Provides implicit confidence scores (strong consensus = high confidence)
- Catches errors that would slip through in single-generation approaches
Cost Considerations:
Generating 10 samples instead of 1 means 10x the API cost, but the per-query expense remains remarkably affordable with current pricing (November 2025):
Without prompt caching (500-token prompt, 800-token response per sample):
- GPT-5: Approx. €0.08 per aggregated query (10 samples)
- GPT-4o: Approx. €0.10 per aggregated query (10 samples)
- Claude Sonnet 4.5: Approx. €0.12 per aggregated query (10 samples)
- Claude Opus 4: Approx. €0.58 per aggregated query (10 samples)
With prompt caching (90% discount on repeated prompts):
- GPT-5: Approx. €0.07 per aggregated query - best value
- GPT-4o: Approx. €0.09 per aggregated query
- Claude Sonnet 4.5: Approx. €0.11 per aggregated query
- Claude Opus 4: Approx. €0.53 per aggregated query
Key insight:
Prompt caching automatically reduces costs when you reuse the same prompt structure across multiple samples. For self-aggregation, this means 8-13% savings with minimal setup. Both Anthropic and OpenAI offer caching, making this technique even more cost-effective than when it was first introduced.
For high-stakes decisions (financial projections, contract analysis), even the premium Opus 4 pricing of €0.53 per aggregated query easily justifies the accuracy improvement.
Copy-Paste Template: Basic Self-Consistency Implementation
You will solve the following problem using self-consistency.
Problem: [Insert your business problem here]
Instructions:
- Generate 10 different reasoning paths to solve this problem
- Use diverse approaches - consider different methods, perspectives, and calculation techniques
- For each reasoning path, show your step-by-step thinking
- At the end of each path, clearly state your final answer in the format: FINAL ANSWER: [answer]
- After generating all 10 paths, list all final answers and identify which answer appeared most frequently
- Present the most consistent answer as your recommendation
Please structure your response as follows:
Reasoning Path 1:
[Your detailed reasoning]
Final Answer: [answer]
Reasoning Path 2:
[Your detailed reasoning]
Final Answer: [answer]
[Continue for all 10 paths]
Aggregation:
Answer A appeared: [X] times
Answer B appeared: [Y] times
Answer C appeared: [Z] times
Most Consistent Answer: [The answer that appeared most frequently]
Confidence: [X/10 paths agreed on this answer]
Advanced Template with Weighted Aggregation:
You will solve the following problem using self-consistency with quality-weighted aggregation.
Problem: [Insert your business problem here]
Instructions:
- Generate 10 different reasoning paths to solve this problem
- For each path, rate your confidence in the reasoning quality (1-5 scale)
- Use diverse approaches and show step-by-step thinking
- Clearly state your final answer in format: Final Answer: [answer] | Confidence: [1-5]
- Aggregate by weighted voting: multiply each answer's frequency by its average confidence score
Structure as:
Reasoning Path 1:
[Detailed reasoning]
Final Answer: [answer] | Confidence: [1-5]
[Continue for all 10 paths]
Weighted Aggregation:
Answer A: appeared [X] times, average confidence [Y], weighted score [X*Y]
Answer B: appeared [W] times, average confidence [Z], weighted score [W*Z]
Recommended Answer: [Highest weighted score]
What Is Prompt Caching and Why Does It Matter?
Prompt caching is a cost-saving feature offered by both Anthropic and OpenAI that dramatically reduces expenses for repeated prompts. Here's how it works:
When you send the same prompt structure multiple times (like in self-aggregation, where you run the same question 10 times), the API provider stores the "prompt" portion in cache for 5-10 minutes. Subsequent requests within that window get a 50-90% discount on cached tokens.
For self-aggregation, this means:
- Your first sample pays full price for the prompt
- Samples 2-10 get a massive discount on the repeated prompt portion
- You only pay full price for the unique output each time
No code changes required for GPT-5/GPT-4o - caching activates automatically when you repeat prompts. For Claude, you mark which parts to cache with a simple parameter. The 5-10 minute cache window perfectly suits self-aggregation workflows where all 10 samples typically run within seconds of each other.
Bottom line: What would have cost €0.80 per query two years ago now costs €0.07 with GPT-5 and caching. That's a 91% reduction, making self-aggregation accessible even for cost-conscious SMBs.
SME Example: Financial Forecasting for an E-commerce Business
Let me show you how self-aggregation works in practice with a realistic scenario that demonstrates both its power and limitations.
The Scenario:
Sarah runs "Celtic Craft Co," a Dublin-based online retailer selling handmade Irish goods. She's planning inventory for Q4 2024 and needs to forecast November revenue.
She has these data points:
- Last November: €42,300 revenue
- Overall year-over-year growth: 15%
- New marketing campaign launched in October increased traffic by 25%
- Product line expansion added 8 new SKUs
- Euro/Dollar exchange rate shifted, affecting 30% of sales (US customers)
- Black Friday falls on November 29th this year (2024)
Without Self-Aggregation (Single-Shot Approach):
Sarah asks Claude: "Based on this data, what should I forecast for November 2024 revenue?"
Single response: "Considering your 15% YoY growth and the 25% traffic increase, I'd project approximately €54,000 for November. The new products and marketing boost should offset any currency headwinds."
This sounds reasonable, but notice the model made several hidden assumptions: it weighted marketing impact heavily, assumed the new products would contribute proportionally, and didn't deeply consider the Black Friday timing. Sarah has one number and no way to verify its reliability.
With Self-Aggregation:
Sarah uses the self-consistency template with 10 reasoning paths. Here's what emerges:
- Path 1 (baseline growth model): €48,645 (simply applies 15% growth)
- Path 2 (marketing-weighted): €52,875 (emphasises traffic increase)
- Path 3 (conservative): €47,200 (accounts for currency drag)
- Path 4 (optimistic): €56,100 (new products + marketing synergy)
- Path 5 (Black Friday focused): €51,500 (extra weighting on final week)
- Path 6 (historical trend analysis): €49,800 (examines seasonality patterns)
- Path 7 (segmented forecast): €50,400 (breaks down by product category)
- Path 8 (currency-adjusted): €48,900 (explicitly models FX impact)
- Path 9 (marketing decay model): €50,200 (assumes campaign effectiveness fades)
- Path 10 (composite approach): €51,000 (averages multiple methodologies)
Aggregation Results:
- Range: €47,200 to €56,100
- Median: €50,250
- Most common bracket (€49,000-€52,000): 7 out of 10 projections
- Strong consensus emerging around €50,000-€51,000
Business Impact:
Instead of receiving one potentially overconfident number, Sarah now has:
- A validated range: €49k-€52k captures most projections
- Confidence in the estimate: 70% of reasoning paths clustered tightly
- Risk visibility: The optimistic scenario (€56k) shows possible upside, while the conservative one (€47k) reveals downside risk
- Better planning: She orders inventory for €51k baseline with buffer stock for €54k scenario
- Transparent assumptions: Each reasoning path revealed different factors, helping her understand what drives the forecast
The cost? Approximately €0.11 for this aggregated query using Claude Sonnet 4.5 (with prompt caching enabled). For a decision involving thousands of euros in inventory investment, that's trivial insurance.
Real Outcome:
When November arrives, actual revenue hits €50,300 - right in the middle of the predicted range. Without self-aggregation, Sarah might have over-ordered based on the optimistic single-shot projection or under-ordered from excessive caution. The aggregated forecast gave her confidence to stock appropriately.
Advanced Aggregation Strategies Beyond Simple Voting
While majority voting forms the foundation of self-consistency, several advanced aggregation strategies can improve results for specific use cases. Let's explore when and how to use each approach.
1. Majority Voting (The Baseline)
This is the standard approach from the original Wang et al. (2022) research. Count how many times each distinct answer appears and select the most frequent one.
Best for:
- Problems with discrete, clearly defined answers (numbers, yes/no, multiple choice)
- Mathematical calculations where answers are exact values
- Classification tasks with fixed categories
Implementation: Generate 10-40 samples, extract final answers, count frequency, select the mode.
Limitations: Treats all reasoning paths equally regardless of quality. A path with obvious logical flaws counts the same as one with rigorous step-by-step verification.
2. Weighted Voting Based on Reasoning Quality
Assign quality scores to each reasoning path based on factors like:
- Logical coherence (does the reasoning flow make sense?)
- Completeness (were all relevant factors considered?)
- Transparency (can you follow the logic clearly?)
- Use of evidence (does it cite specific data points?)
Then weight each answer by its reasoning quality score before aggregating.
Best for:
- Complex business decisions where reasoning quality matters
- Tasks where you can quickly assess argument strength
- Situations where some approaches are inherently more rigorous than others
Implementation: Either manually score reasoning paths or use a second LLM call to rate each path's quality on a 1-5 scale, then multiply frequency by average quality score.
3. Confidence-Based Aggregation
Instead of just counting answers, weight them by the model's own probability estimates. Recent research on confidence-improved self-consistency shows this can significantly boost sample efficiency - achieving the same accuracy with fewer samples.
The model generates not just answers but probability scores for each token in the answer. Aggregate using these confidence weights rather than simple vote counting.
Best for:
- Reducing the number of samples needed (10 instead of 40)
- Tasks where model confidence correlates with correctness
- Scenarios where computational cost is a significant constraint
Implementation: Use the log probabilities returned by the API to weight each answer. Answers generated with higher confidence get more voting weight.
Caveat: This requires API access to token probabilities, which not all providers expose.
4. Soft Self-Consistency for Open-Ended Tasks
Traditional majority voting requires exact matches to tally votes. But what if your task generates open-ended outputs where valid answers won't match exactly?
Soft self-consistency solves this by using semantic similarity instead of exact matching. Calculate how similar each answer is to all others (using embeddings or LLM-as-judge), then select the answer most semantically similar to the cluster of responses.
Best for:
- Code generation (where many valid implementations exist)
- Open-ended business advice
- Creative problem-solving with multiple valid approaches
- Any task where answers should be similar in meaning but not identical in wording
Implementation:
- Generate 10 diverse solutions
- Use embeddings (like OpenAI's text-embedding-3-large) to vectorise each answer
- Calculate the cosine similarity between all pairs
- Select the answer with the highest average similarity to all others (the "centroid" response)
5. Universal Self-Consistency (LLM-as-Judge)
Instead of mechanical aggregation rules, use another LLM call to judge which answer is most consistent or reliable among the candidates.
Chen et al. (2023) introduced this approach, showing that LLMs can effectively evaluate their own outputs when given multiple candidates.
Best for:
- Tasks requiring nuanced judgment
- Situations where answers can't be easily compared mechanically
- Free-form generation where quality matters more than exact consistency
Implementation:
- Generate 10 reasoning paths
- Present all 10 final answers to the LLM with this prompt: "Which of these answers is most accurate and well-reasoned? Explain your choice."
- Use the LLM's selection as your final answer
Cost consideration: This adds one extra LLM call but reduces the need for complex aggregation logic.
When to Use Each Method: Decision Matrix
- Exact numerical answers needed? → Majority voting
- Limited budget, need efficiency? → Confidence-based aggregation
- Open-ended creative output? → Soft self-consistency with embeddings
- Need quality assessment? → Weighted voting or LLM-as-judge
- Is maximum reliability critical? → Combine multiple methods (weighted + confidence)
For most Irish SMB applications, starting with simple majority voting over 10-15 samples provides the best bang for your buck. Upgrade to advanced methods only when results justify the added complexity.
Combining Self-Aggregation with Other Techniques from This Series
The real power of self-aggregation emerges when you combine it with other prompting techniques we've covered in this series. Think of these methods as building blocks that stack together for increasingly reliable AI outputs.
Self-Aggregation + Self-Refine: The Double-Check System
Remember how Self-Refine (covered in our earlier posts) has the model critique and improve its own answer? You can chain this with self-aggregation:
- Generate 10 initial reasoning paths with self-aggregation
- Take the majority-vote winner
- Apply Self-Refine: have the model critique this answer and generate an improved version
- Generate 10 more diverse paths starting from the refined answer
- Final aggregation across all 20 paths
This double-check system catches errors that slip through either technique alone. It's overkill for routine queries but invaluable for high-stakes decisions like contract interpretation or financial modelling.
Cost: Roughly 20× single queries, but for a €50,000 business decision, spending €1.40-2.20 on AI verification (using GPT-5 or Claude Sonnet 4.5) is prudent insurance.
Self-Aggregation + Contrastive Reasoning: Learning from Mistakes
In our post on contrastive prompting, we explored how asking the model to generate both correct and incorrect solutions improves accuracy. Combine this with aggregation:
For the following problem, generate 10 diverse solution attempts.
For 5 attempts: Solve correctly, showing valid reasoning
For 5 attempts: Solve incorrectly on purpose, identifying common mistakes
Then aggregate the 5 correct solutions to find the most consistent answer. Finally, verify this answer doesn't contain any of the errors identified in the incorrect attempts.
This technique helps the model avoid systematic biases—errors that might appear consistently across multiple "correct" attempts because the model has a blind spot.
Self-Aggregation + Structured Output Formatting
When aggregating, you need consistent answer formats. Combine self-consistency with structured output requirements:
Generate 10 solutions. Each MUST end with answers in this exact format:
Numerical_Answer: [number only]
Confidence: [low/medium/high]
Key_Assumptions: [bullet list]
This allows easy parsing for aggregation while capturing uncertainty and assumptions.
This proves particularly valuable for business intelligence queries where you're aggregating forecasts or estimates - you want not just the number but the reasoning and confidence behind it.
Self-Aggregation + Multi-Step Verification
For complex multi-part problems (like financial models with 5-6 calculation steps), apply self-consistency at each stage:
- Step 1: Calculate baseline revenue (aggregate 10 approaches)
- Step 2: Apply growth rate (aggregate 10 methods)
- Step 3: Adjust for seasonality (aggregate 10 adjustments)
- Step 4: Factor in market conditions (aggregate 10 scenarios)
- Final aggregation: Combine the consensus answers from each step
This cascading verification ensures errors don't compound through multi-step reasoning. Each stage gets validated before feeding into the next.
Building a Comprehensive AI Quality Assurance Workflow
Here's how an Irish consulting firm might combine everything for client deliverables:
Phase 1: Initial Analysis (Self-Aggregation)
- Generate 15 diverse analytical approaches
- Identify majority consensus answer
Phase 2: Critical Review (Contrastive Reasoning)
- Generate 5 counter-arguments or alternative interpretations
- Verify the consensus answer withstands scrutiny
Phase 3: Refinement (Self-Refine)
- Critique the consensus answer for weaknesses
- Generate improved version incorporating the critique
Phase 4: Final Validation (Second Round Aggregation)
- Generate 10 more approaches using the refined answer as a starting point
- Final aggregation across all attempts
- Human review with confidence scores and key assumptions surfaced
Result: Enterprise-grade analysis with layered verification, suitable for client-facing deliverables.
Cost: Approximately €2-4 per comprehensive analysis using Claude Sonnet 4.5 or GPT-5 (with prompt caching). For consulting work billed at €80-120 per hour, this represents a trivial expense with massive reliability gains.
The key insight? Don't think of these techniques as competing alternatives - they're complementary tools that work better together than apart. Start simple with basic self-aggregation, then layer in additional techniques as your use case complexity and stakes increase.
Implementation Considerations for Irish SMBs
Self-aggregation delivers impressive accuracy gains, but implementing it effectively requires thinking through several practical considerations specific to your business context. Let's address the real-world decisions Irish SMEs face when adopting this technique.
Cost-Benefit Analysis: When Does Accuracy Justify Extra API Calls?
The fundamental trade-off is simple: 10x the API calls means roughly 10x the cost. Here's how to think about when that makes sense:
High-value decisions (self-aggregation is definitely worthwhile):
- Financial projections affecting inventory purchases of €5,000+
- Contract analysis where errors could trigger legal disputes
- Technical specifications for manufacturing (where mistakes cost thousands to fix)
- Compliance checks where getting it wrong triggers regulatory penalties
- Strategic planning decisions (market entry, hiring, major investments)
Rule of thumb: If an error costs more than €100 to fix, spending €0.50-€2 on verified AI analysis is excellent insurance.
Low-value decisions (single queries probably fine):
- Routine customer support responses
- Internal brainstorming and ideation
- First-draft content creation
- Quick factual lookups
- Low-stakes scheduling and planning
The sweet spot: Reserve self-aggregation for the 10-20% of your AI queries where accuracy really matters. Use single-shot generation for the routine 80%.
Optimal Sample Sizes: Finding Your Accuracy/Cost Balance
How many samples should you generate? Research and practical testing reveal clear patterns:
5 samples: Minimal improvement over single query (typically 3-5% accuracy gain)
- Use for: Quick sanity checks, low-stakes verification
10 samples: Sweet spot for most business applications (7-12% accuracy gain)
- Use for: Standard high-stakes decisions, typical financial analysis
- Cost: €0.07-€0.12 per aggregated query (GPT-5 or Claude Sonnet 4.5 with caching)
15-20 samples: Diminishing returns start (10-15% accuracy gain)
- Use for: Critical decisions, regulatory compliance, contract analysis
- Cost: €0.11-€0.18 per aggregated query
30-40 samples: Maximum accuracy (15-18% accuracy gain)
- Use for: Mission-critical applications only, very high financial stakes
- Cost: €0.21-€0.36 per aggregated query (using GPT-5 with caching)
Above 40 samples: Marginal gains flatten out significantly
Practical guidance: Start with 10 samples for high-stakes queries. If you're still seeing errors or high variance in answers, bump to 15-20. Only go above 20 when money or reputation is directly on the line.
Balancing Speed vs. Accuracy
Self-aggregation increases latency - you're waiting for 10 sequential API calls (or parallel calls if your implementation supports it).
Latency considerations:
- Sequential generation: 10 samples × 30 seconds average = 5 minutes total
- Parallel generation: Still ~30-60 seconds (API rate limits apply)
When speed matters more:
- Real-time customer interactions (chatbots, live support)
- Rapid prototyping and brainstorming sessions
- Scenarios where you'll manually review output anyway
Speed optimisation strategies:
- Use parallel API calls where possible (most libraries support this)
- Generate fewer samples for time-sensitive queries (5 instead of 10)
- Use faster models for aggregation (GPT-5-mini for 10 samples, then GPT-5.1 for final refinement)
- Pre-generate aggregated answers for common queries (FAQ databases)
Monitoring and Measuring Improvement
How do you know self-aggregation is actually working for your specific applications? Establish measurement systems:
Before implementation:
- Run 50-100 test queries using single-shot generation
- Manually verify accuracy (or use ground truth where available)
- Calculate baseline accuracy percentage
After implementation:
- Run the same test queries using self-aggregation
- Calculate new accuracy percentage
- Measure: (New Accuracy - Baseline Accuracy) / Cost Increase
Example metrics for an accounting firm:
- Baseline: 73% accuracy on VAT calculation queries (single shot)
- Self-aggregation: 89% accuracy (10 samples)
- Improvement: +16 percentage points
- Cost increase: €0.15 → €1.50 per query (10× increase)
- Value: Each error costs ~€200 in accountant time to fix
- ROI: Preventing 16% of errors saves €32 per query at cost of €1.35 = massive positive ROI
Track over time:
- Create a dashboard monitoring aggregation consistency scores
- High variance across samples = complex query or model uncertainty
- Low variance = model confidence (though verify it's not confident about wrong answers)
GDPR Considerations for Irish Businesses
When processing customer data through multiple AI generations, data protection becomes a consideration:
Key principles:
- Data minimisation: Only include customer data necessary for the specific task
- Processing purpose: Self-aggregation qualifies as "accuracy improvement" which is a legitimate purpose
- Third-party processing: Your DPA (Data Processing Agreement) with OpenAI/Anthropic should cover multiple generations
- Retention: Multiple samples shouldn't be stored longer than necessary
- Transparency: Update your privacy policy if you're using AI extensively for customer-facing decisions
Practical recommendations:
- Anonymise data before sending to AI where possible (replace names with placeholders)
- Don't log or store the 10 individual reasoning paths - only the final aggregated answer
- For sensitive financial or medical data, consider on-premise models with self-aggregation
- Verify your API provider's data retention policies align with GDPR (most major providers delete data after 30 days max)
Example privacy policy language:
"We may use AI-powered tools to analyse business data and improve decision accuracy. These tools process data through multiple analytical approaches to verify results. We maintain GDPR-compliant data processing agreements with all AI service providers."
Getting Started: A Practical 30-Day Implementation Plan
Week 1: Baseline and Testing
- Identify 3-5 high-stakes query types where accuracy matters
- Run 20 test queries using single-shot generation
- Manually verify accuracy, calculate baseline
Week 2: Initial Implementation
- Implement self-aggregation with 10 samples on one query type
- Run the same 20 test queries, measure accuracy improvement
- Calculate cost-per-query and ROI
Week 3: Optimisation
- Experiment with 5, 10, and 15 samples to find the optimal balance
- Test different aggregation strategies (majority vote vs. weighted)
- Refine prompts based on consistency scores
Week 4: Rollout and Documentation
- Expand to all identified high-stakes query types
- Document the prompts and processes for your team
- Set up a monitoring dashboard tracking accuracy and costs
Month 2 and beyond:
- Gradually identify additional use cases
- Combine with other techniques (Self-Refine, contrastive reasoning)
- Build your organisation's "AI quality assurance" playbook
The key is starting small, measuring rigorously, and expanding based on verified results rather than assumptions. Let the data guide where self-aggregation delivers value for your specific business.
Common Pitfalls and How to Avoid Them
Even with perfect understanding of self-aggregation theory, implementation challenges can undermine your results. Here are the mistakes we see most often and how to sidestep them.
Pitfall 1: Using Too Few Samples
The mistake: Generating only 3-5 samples to save costs, expecting similar results to 10-20 samples.
Why it fails: Research shows that accuracy improvements scale with sample size up to about 40 samples. With only 3-5 samples, you're barely improving over single-shot generation - maybe 3-5% accuracy gain versus 10-15% with proper sampling.
The math: With 5 samples where each has 70% individual accuracy, there's only a 65% chance the majority vote is correct. With 15 samples at the same accuracy, that jumps to 85% probability.
How to avoid: Default to 10 samples for high-stakes queries. Yes, it costs more, but that's the whole point - you're paying for reliability. If budget is truly constrained, use fewer samples for lower-stakes queries, but don't kid yourself that 5 samples on critical work will deliver full benefits.
Pitfall 2: Insufficient Diversity in Reasoning Paths
The mistake: Generating multiple samples but they all use essentially the same approach - just with slight wording variations.
Why it fails: Self-aggregation's power comes from diverse reasoning paths catching different errors. If all 10 samples use the same flawed method, you'll get consistent wrong answers. The model needs true diversity in its reasoning approaches.
Example: Asking for revenue forecast 10 times might yield 10 variations of "apply the growth rate" - but none consider seasonality, market conditions, or customer segmentation. You get false confidence in a potentially incomplete answer.
How to avoid:
- Set temperature high: Use temperature 0.8-1.0 to encourage diverse generations (default is often 0.7)
- Explicit diversity prompting: "Use 10 completely different analytical methods: trend analysis, comparable company analysis, regression modelling, seasonal decomposition, customer cohort analysis, market share estimation..."
- Verify diversity: Quickly scan the first few reasoning paths—if they look identical, increase temperature or rephrase the diversity requirement
Pitfall 3: Applying to Subjective or Open-Ended Tasks
The mistake: Using majority voting on creative writing, opinion questions, or subjective judgments where there is no single "correct" answer.
Why it fails: Self-aggregation assumes multiple reasoning paths should converge on the same answer. For subjective tasks, diversity is the goal, not a bug to be voted away.
Bad application: "Write me 10 product descriptions, then select the most common phrasing." You've just averaged out all the creative variation - the worst of both worlds.
Good application: "Generate 10 financial projections using different methods, then select the most consistent estimate."
How to avoid: Ask yourself: "Is there an objectively correct answer to this question?" If not, self-aggregation is the wrong tool.
Use it for:
- Mathematical/numerical questions
- Factual analysis with verifiable claims
- Logical reasoning with clear right/wrong answers
- Technical specifications
Avoid it for:
- Creative content generation
- Stylistic choices
- Opinion-based recommendations
- Brainstorming and ideation
Pitfall 4: Forgetting to Standardise Answer Formats
The mistake: Generating 10 diverse responses where final answers are stated differently: "€5,000", "five thousand euros", "approximately 5k", "around five thousand."
Why it fails: Majority voting requires identifying equivalent answers. If your €5,000 answer appears three different ways, it might lose to a wrong answer that appears four times consistently.
How to avoid:
- Explicit format instructions: "State your final answer as: Final_Answer: [numerical value only, no currency symbols]"
- Post-processing: Before aggregation, parse and normalise answers (convert all to numbers, strip currency symbols, round to the same decimals)
- Structured output: Use JSON or other structured formats that enforce consistent formatting
Good template addition:
For each reasoning path, end with this exact format:
Final_Numerical_Answer: [digits only]
Confidence: [1-5]
Pitfall 5: Over-Relying on Aggregation for Simple Tasks
The mistake: Running 15-sample self-aggregation on queries where single-shot accuracy is already 95%+.
Why it fails: You're spending 15x the cost for maybe 2-3% accuracy improvement. The marginal gains don't justify the expense.
Example: "What's the VAT rate in Ireland?" Single query gets this right 99% of the time. Running 15 samples wastes money.
How to avoid:
- Establish accuracy baselines for different query types through testing
- Apply self-aggregation selectively to query types with <85% baseline accuracy
- Create a decision matrix: Simple factual lookups: single query
- Straightforward calculations: single query with self-reflection
- Complex analysis: 10-sample aggregation
- Mission-critical decisions: 15-20 sample aggregation with additional verification
Pitfall 6: Ignoring Consistency Scores
The mistake: Just taking the majority vote answer without looking at how strong the consensus was.
Why it fails: 6 out of 10 samples agreeing tells you something very different from 10 out of 10 samples agreeing. Low consensus might indicate:
- The question is ambiguous
- Multiple answers are actually valid
- The model is uncertain and you should investigate further
Example:
- Query 1: 9 out of 10 samples say "€52,000" → High confidence
- Query 2: 4 samples say "€52,000", 3 say "€48,000", 3 say "€56,000" → Low confidence, dig deeper
How to avoid: Always track and report consensus strength:
MOST CONSISTENT ANSWER: €52,000
CONSENSUS: 9/10 samples (90% agreement)
ALTERNATIVE ANSWERS: €51,800 (1 sample)
When consensus falls below 70%, that's a red flag to either generate more samples or manually review the diversity of reasoning.
Pitfall 7: Not Validating the Technique for Your Domain
The mistake: Assuming published research results will automatically transfer to your specific business domain without testing.
Why it fails: Self-aggregation shows 15%+ improvements on mathematical reasoning benchmarks, but your domain might have different characteristics. Maybe your queries already have high baseline accuracy. Maybe the model lacks domain knowledge, so all reasoning paths make the same category of mistake.
How to avoid: Always run domain-specific validation:
- Create 50-100 test queries representative of your actual use cases
- Establish ground truth (correct answers verified by domain experts)
- Measure: Baseline accuracy (single query) vs. Self-aggregation accuracy (10 samples)
- Calculate ROI for your specific domain
- Adjust strategy based on results
Don't assume - measure. The few hours spent on rigorous testing will save you from months of overpaying for minimal gains (or under-investing in a technique that could transform your accuracy).
Measuring Success: How to Know Self-Aggregation Is Working
You've implemented self-aggregation, you're generating 10 samples per query, your costs have increased - but are you actually
getting better results? Here's how to measure success rigorously and make data-driven decisions about your implementation.
Step 1: Establish Accuracy Baselines
Before you can measure improvement, you need to know where you started. This requires creating a test set with verified correct answers.
For an Irish accounting firm:
- Select 50 real client questions your AI system will handle
- Have senior accountants provide verified correct answers
- Run each question through your AI once (single-shot baseline)
- Calculate accuracy: What percentage of AI answers match expert answers?
Example baseline results:
- Simple factual queries (tax rates, deadlines): 94% accurate
- Numerical calculations (VAT, deductions): 78% accurate
- Complex analysis (tax strategy recommendations): 61% accurate
- Multi-step problems (full tax return review): 52% accurate
Now you know where accuracy improvement matters most. Spending 10× the cost to boost simple queries from 94% to 96% makes no sense. But boosting complex analysis from 61% to 82%? That could be transformative.
Step 2: Implement Self-Aggregation on High-Impact Categories
Focus your implementation where baseline accuracy is lowest and stakes are highest:
- Take your worst-performing category (e.g., multi-step problems at 52%)
- Run the same 50 test queries using self-aggregation with 10 samples
- Calculate new accuracy percentage
Example results:
- Multi-step problems: 52% → 71% (19-point improvement)
- Complex analysis: 61% → 78% (17-point improvement)
- Numerical calculations: 78% → 87% (9-point improvement)
Step 3: Calculate Cost-Adjusted Performance
Accuracy improvement alone doesn't tell the whole story - you need to factor in cost increases.
The formula:
Cost-Effectiveness Score = (Accuracy Improvement %) / (Cost Multiplier)
Where:
- Accuracy Improvement = New Accuracy - Baseline Accuracy
- Cost Multiplier = (Cost per aggregated query / Cost per single query)
Example calculation:
- Multi-step problems: 19% improvement / 10× cost = 1.9 score
- Complex analysis: 17% improvement / 10× cost = 1.7 score
- Numerical calculations: 9% improvement / 10× cost = 0.9 score
Interpretation:
- Score > 1.5: Excellent cost-effectiveness, expand usage
- Score 1.0-1.5: Good value, use selectively
- Score < 1.0: Marginal value, consider alternatives or fewer samples
Step 4: Track Consistency Scores Over Time
Consistency score = (Votes for winning answer / Total samples)
Track this metric across your queries. It reveals patterns:
High consistency (80-100% agreement):
- Model is confident
- Question is well-posed
- Domain is well-understood by the model
Medium consistency (60-80% agreement):
- Some ambiguity present
- Multiple approaches yielding slightly different results
- May benefit from additional samples or clarification
Low consistency (<60% agreement):
- Question may be ambiguous
- Model lacks clear domain knowledge
- Multiple answers might actually be valid
- Red flag to investigate manually
Dashboard example:
July 2024 Consistency Scores:
Financial projections: 76% average (good)
Contract interpretation: 58% average (review needed)
Technical specs: 89% average (excellent)
Step 5: Monitor Real-World Error Rates
Accuracy on test sets matters, but what counts is real-world performance. Track errors caught by downstream review:
Before self-aggregation:
- 15 errors per 100 queries caught by human review
- 3 errors per 100 reached clients (caught by client feedback)
After self-aggregation:
- 6 errors per 100 queries caught by human review (60% reduction)
- 1 error per 100 reached clients (67% reduction)
This real-world validation matters more than test set accuracy.
Step 6: Calculate Return on Investment
Here's where it all comes together. What's the business value of improved accuracy?
Example ROI calculation for a legal firm:
Costs:
- Baseline: 500 queries/month × €0.008 = €4/month (single GPT-5 queries)
- With self-aggregation: 500 queries × €0.07 = €35/month (GPT-5 with prompt caching, 10 samples)
- Increased cost: €31/month
Benefits:
- Errors reduced from 15/100 to 6/100
- Each error caught early saves 1.5 hours paralegal time (€60/hour) = €90 saved
- 45 errors prevented per month × €90 = €4,050/month saved
- Errors reaching clients reduced by 10/month, each potentially costing €500 in client relationship damage = €5,000/month saved
Net benefit: €8,735/month gain for €31/month investment ROI: 28,000%+ return
Even if we're extremely conservative and assume benefits are just 10% of the estimate, it's still 2,700%+ ROI.
Step 7: A/B Testing Different Sample Sizes
Once basic self-aggregation is working, optimise by testing different sample counts:
Test design:
- Run 100 queries with 5 samples each
- Run 100 queries with 10 samples each
- Run 100 queries with 15 samples each
- Run 100 queries with 20 samples each
Measure:
- Accuracy at each level
- Average cost per query at each level
- Diminishing returns curve
Example findings:
- 5 samples: 68% accuracy, €0.75/query
- 10 samples: 76% accuracy, €1.50/query (sweet spot)
- 15 samples: 79% accuracy, €2.25/query
- 20 samples: 80% accuracy, €3.00/query
Conclusion: For this firm's use cases, 10 samples hits the optimal accuracy/cost balance. Moving to 15+ samples shows diminishing returns.
Creating Your Self-Aggregation Dashboard
Pull all these metrics together in a monthly dashboard:
=== SELF-AGGREGATION PERFORMANCE DASHBOARD ===
Period: August 2024
ACCURACY METRICS:
├─ Overall accuracy: 78% (↑ from 63% baseline)
├─ High-stakes queries: 82% (↑ from 58%)
└─ Low-stakes queries: 91% (↑ from 87%)
CONSISTENCY METRICS:
├─ Average consensus: 74%
├─ High confidence queries (>80%): 62%
└─ Low confidence queries (<60%): 11% (review flagged)
COST METRICS:
├─ Monthly API cost: €42 (↑ from €4)
├─ Cost per query: €0.07 average (GPT-5 with caching)
└─ Queries using self-aggregation: 60% of total
VALUE METRICS:
├─ Errors prevented: 52 this month
├─ Estimated time saved: 78 hours
├─ Estimated cost saved: €4,680
└─ Net ROI: 11,000%
OPTIMISATION OPPORTUNITIES:
└─ Contract analysis: Consider 15 samples (currently 10)
└─ Simple queries: Reduce to 5 samples or single-shot
This dashboard tells you at a glance whether self-aggregation is delivering value, where to expand it, and where to pull back
.
The Ultimate Success Metric: Business Confidence
Beyond numbers, track this softer metric: Are your team members more confident using AI outputs?
Before self-aggregation, maybe they reviewed every AI answer skeptically. After implementing aggregation with visible consensus scores, do they trust high-confidence outputs (90%+ agreement) enough to act on them directly?
If your team is spending less time second-guessing the AI and more time leveraging its analysis, that's success - even if it's harder to quantify than accuracy percentages.
Conclusion
Self-aggregation represents one of the most powerful yet underutilised techniques in the prompting toolkit. By generating multiple reasoning paths and intelligently aggregating their outputs, you transform unreliable AI guesses into verified business intelligence - all without specialised training or fine-tuning.
The research backing this approach is rock-solid. Wang et al.'s 2022 Google Brain study demonstrated 10-18% accuracy improvements across diverse reasoning tasks, and subsequent research has only expanded our understanding of when and how to apply these techniques most effectively.
For Irish SMBs navigating the practical realities of AI adoption, self-aggregation offers something rare: a technique with strong theoretical foundations that also delivers immediate, measurable business value. Yes, it increases API costs by 5-20x for individual queries. But when each error costs you hours of expert time to fix - or worse, damages client relationships - spending seven to fifty cents per query to boost accuracy by 15 percentage points is obvious value.
The economics have become even more compelling in late 2025 with GPT-5's aggressive pricing and widespread prompt caching support. What used to cost €0.80 per aggregated query now runs at €0.07 with current models and caching - making self-aggregation accessible even for cost-conscious businesses.
The key is strategic application. Don't aggregate everything - that's wasteful. Reserve self-aggregation for the 10-20% of your AI queries where accuracy truly matters: financial projections, contract analysis, technical specifications, compliance checks, strategic planning. For routine queries and creative tasks, single-shot generation remains perfectly adequate.
In one of our next articles in the AI Prompting Series, we'll bring everything together - Chain-of-Thought, Self-Refine, contrastive reasoning, self-aggregation, and the other techniques we've covered - into comprehensive prompting frameworks that deliver enterprise-grade AI performance for your business. We'll show you how to build your own "AI quality assurance" system that adapts these techniques to your specific domain and accuracy requirements.
Ready to implement self-aggregation in your workflows? Start with these three steps:
- Identify 3-5 high-stakes query types where AI errors cost you time or money
- Run a baseline test of 20-50 queries using single-shot generation, measuring accuracy
- Implement the copy-paste template from this article with 10 samples, measure improvement
After one week, you'll have concrete data showing whether self-aggregation delivers value for your specific use cases. Then systematically expand to other critical applications where reliability matters more than speed.
The future of reliable AI isn't waiting for perfect models - it's using the models we have more intelligently. Self-aggregation gives you that intelligence today.
Additional Resources
Research Papers:
- Self-Consistency Improves Chain of Thought Reasoning in Language Models - Wang et al., 2022 (Original foundational paper)
- How Effective Is Self-Consistency for Long-Context Problems? - Recent study on self-consistency limitations and extensions
- Soft Self-Consistency Improves Language Model Agents - Wang et al., 2024 (Advanced aggregation for open-ended tasks)
- Confidence Improves Self-Consistency in LLMs - 2025 research on confidence-weighted aggregation
- Internal Consistency and Self-Feedback in Large Language Models: A Survey - Chen et al., 2024 (Comprehensive survey including Universal Self-Consistency)